합성곱 신경망(CNN, Convolutional Neural Network)
이미지, 음성, 자연어 처리 등 다양한 분야에 사용되는 딥러닝 모델이다.
특히 이미지 처리 분야에서 탁월한 성능을 보여주기 때문에 해당 분야에서 사용된다.
CNN은 인간의 시각 시스템에서 영감을 받아 설계 되었는데, 인간의 뇌는 시각 정보를 처리할 때 작은 부분을 집중적으로 관찰하고 이러한 부분들을 조합하여 전체 이미지를 이해하게 된다.
CNN 또한 작은 필터를 이용하여 지역적인 특성을 도출하고 이를 통해 전체 이미지를 분석하게 된다.
CNN의 대략적인 구조는 아래와 같으며 해당 알고리즘의 결과를 입력층으로 받아들여 딥러닝 학습을 수행하게 된다.
- input_shape : 분석 단위의 크기
- convolutional layer : 필터를 통해 지역적인 특성을 도출
- max pooling layer : convolutional layer에서 도출된 특징을 요약 및 압축
- flatten : 요약 데이터를 계산할 수 있도록 펼친 후 Dense에 삽입
데이터 전처리
shape 조정
CNN 모델에 데이터를 입력하기 위해서는 무조건 데이터가 특정한 형태를 가져야 한다. 때문에 전처리 과정에서 shape를 조정하는 것이 필요하다
데이터를 작은 단위로 나누어 처리하는 배치 처리를 위해 shape를 조절해야하며, CNN 모델 자체의 설계 때문이기도 하다
# 데이터 원본의 shape 확인
x_train.shape, x_val.shape
>>>((60000, 28, 28), (10000, 28, 28))
위의 예시를 들어 설명하자면 내용은 아래와 같다
- 60000 : 데이터의 개수를 의미한다.
- 28, 28 : 이미지의 높이와 너비를 의미한다 위 데이터의 경우 모든 데이터가 28*28 픽셀인 경우이다.
만약 이미지마다 픽셀이 다르다면? 모든 이미지의 픽셀을 통일시켜주어야 한다!!!!!
# shape 조정
x_train = x_train.reshape(60000,28,28,1)
x_val = x_val.reshape(10000,28,28,1)
여기서 28 뒤의 1은 채널의 수를 의미한다
- 1 : 흑백 이미지의 경우 픽셀 값 하나로 표현되므로 채널 수가 1이다
- 3 : 컬러 이미지의 경우 RGB(red, green, blue) 세 가지 채널로 표현되므로 채널 수가 3이다
픽셀 값 정규화
앞서 정규화를 수행했을 때, 0~1 로 정규화를 진행한 것 처럼 해당 데이터도 정규화가 필요하다.
여기서 Min-Max Scaling을 동일하게 사용한다.
그러나 픽셀의 값은 0~255 범위에서 벗어나지 않기 때문에, 원본 데이터 / 255의 값이 정규화 값이 된다.
x_train = x_train / 255.
x_val = x_val / 255.CNN모델의 기본 구조

아래 4가지 를 기억해두자, 모델의 학습 범위라고 할 수 있다.
- Conv2D : 지역적인 특징 도출
- MaxPooling : 요약
- Flatten : 1차원으로 펼치기
- Dense : Output Layer
# 모델 생성 예시
model = Sequential([Input(shape = (28, 28, 1)),
Conv2D(16, kernel_size = 3, padding='same', activation='relu'), # strides=1(default)
MaxPooling2D(pool_size = 2 ), # strides=2(기본값이 pool_size 동일)
Flatten(),
Dense(10, activation='softmax')
])
Input shape
기본적으로 (가로, 세로, 채널)의 형태를 띈다, 정규화를 수행하더라도 원본 픽셀의 크기를 삽입한다는 특징이 있는데, 정규화 후에도 원본의 크기는 동일하기 때문이다.
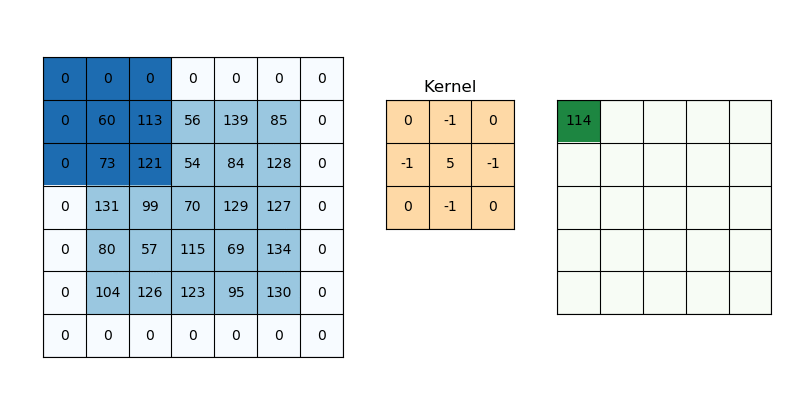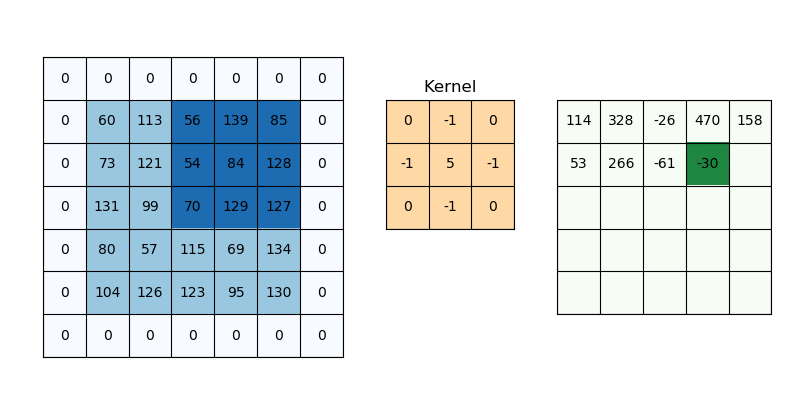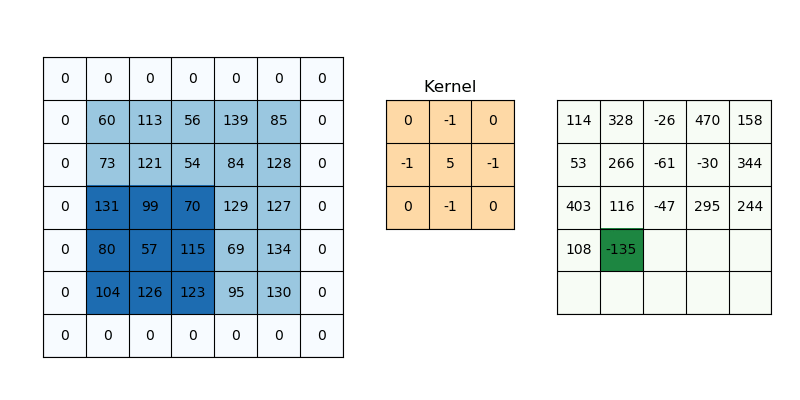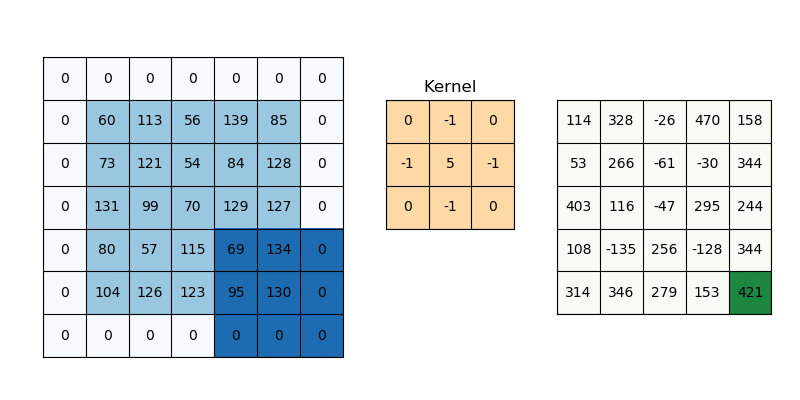
Conv2D
- 16 : 필터(kernel)의 갯수를 의미함. 즉 입력 이미지를 16개의 다른 관점에서 특징을 추출한다는 의미.
- kernel_size=3 : 필터의 크기를 의미, 여기서는 3*3 필터를 의미하며, 5를 입력하면 5*5 필터를 의미하게 된다.
- padding='same' : 출력 이미지의 크기를 입력 이미지와 동일하게 유지하기 위해 사용, 이미지의 주변에 0을 채워넣어 연산시 정보 손실을 줄임, 'valid'로 설정시 패딩 없이 연산하여 출력
- activation='relu' : 활성화 함수로 ReLU를 사용한다는 의미.
- stride=1 : 필터가 이미지 위를 이동하는 간격(보폭)을 의미함
MaxPooling2D
출력 데이터의 크기를 줄이거나 특정 데이터를 강조하기 위해 사용한다.
- pool_size=2 : 풀링을 적용할 크기를 의미함, 위 코드에서는 2*2영역 중 가장 큰 값을 남기게 됨
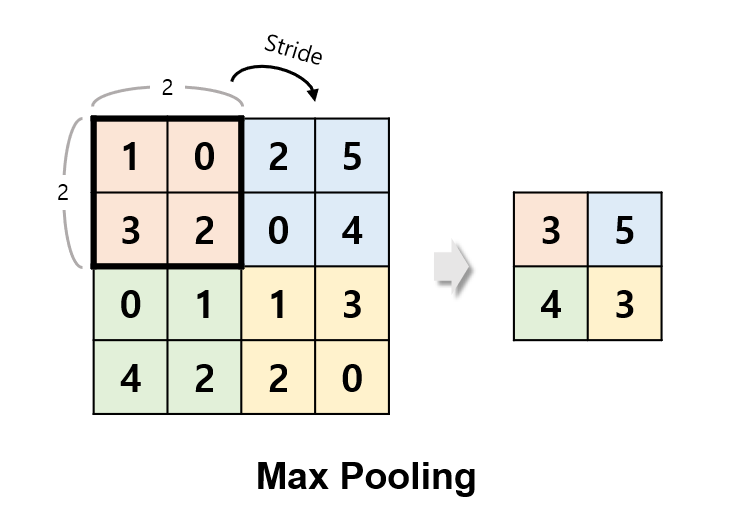
Flatten
최종 예측 결과로 뽑아내기 위해 1차원 혹은 단일의 값으로의 변환

'Study IT > Deep Learning' 카테고리의 다른 글
| 6. LangChain 과 RAG (3) | 2024.11.06 |
|---|---|
| 5. 딥러닝 언어모델 활용 (6) | 2024.11.05 |
| 3. 성능 관리 (0) | 2024.11.05 |
| 2. 분류 모델링 (1) | 2024.11.05 |
| 1. 딥러닝 기초 개념과 회귀 모델링 (1) | 2024.11.04 |